
Robotina and the Goblins: A Tactile knowledge RAG pipeline
Written by:
Martina ‘Documentina’ Welander

Written by:
Martina ‘Documentina’ Welander
Tactile’s Technical Writer and the creator of Robotina
Like most games companies, Tactile is in possession of a 🐉Smaug-worthy treasure trove of documentation. These days, a lot of it is even in One Structured Wiki To Rule Them All rather than our CTO’s brain and that one post-it note from 2019.
A lot – hurrah for us! – but far from all.
There is no stopping knowledge from establishing wild frontier communities in commit messages, ticket descriptions, chats, and scattered READMEs. And, no matter how fabulous or complete the documentation is, you still have to find it, and read it (eek!), and process it for your specific needs, and make sure that you’ve got the whole picture.
It’s Big Brain Stuff, and you were already doing Big Brain Stuff today.
As the person who writes the documentation, I don’t blame my colleagues for just asking someone instead.
Well, what if that someone was a robot and you could chat to it in Slack?
Robotina – the little side project that grew
Robotina exists because I walked past someone’s desk at the exact moment they said “I wish [favorite AI platform] would let me search our wiki” (true story).
I opened VS Code, created a folder named `docindex`, and added some embedded wiki documents to a MeiliSearch index. The 📚Docstack was born, and 🤖Robotina appeared soon after – lo and behold, I had created a little baby RAG (Retrieval-Augmented Generation) pipeline before I knew what that meant.
Many months later, our robo colleague is doing a pretty decent job:
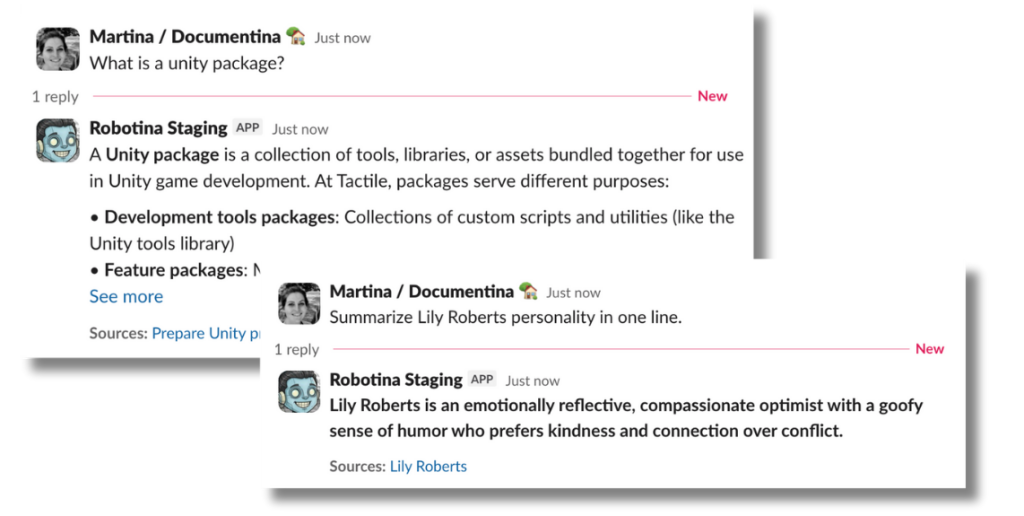
How it works
Robotina sends chat messages to her brain: the Docstack.
The Docstack is a custom app that (among other things) ingests, analyzes, chunks, embeds, and indexes content from sources such as our wiki, public chats, tickets, and even parts of codebases. The Dockstack data goblins (yes, really – life is too serious) do most of the heavy lifting to ensure that Robotina has access to a nice, clean, unified index of embedded content to search.
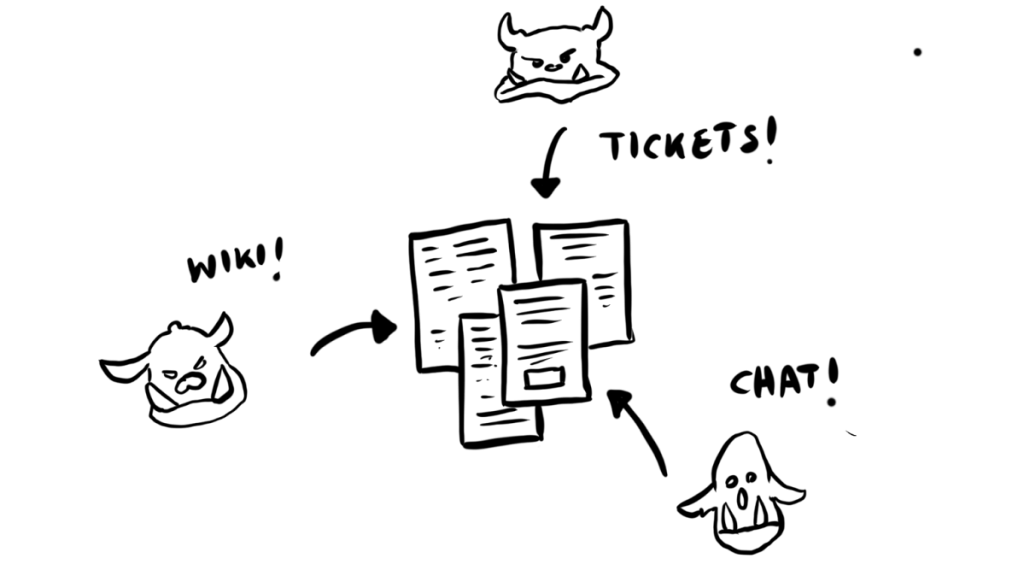
Ingest and chunk!
Each goblin is responsible for breaking a piece of content into smaller chunks. Ideally, a chunk should be able to stand alone – it should explain one concept or answer one question, such as “What is feature meta data?” or “Explain the A/B test group membership calculation”.
Luckily, human beings also like structured, scannable content with meaningful subheadings. If humans liked your docs, you’re already ahead – the robot will probably like it too.
Embed and index!
The magical math part of the Docstack (and of most RAG pipelines) is embedding vectors. We send each chunk of content to an embedding service (which is backed by a specialized embedding model), and it returns a long list of floating point numbers (the vector).
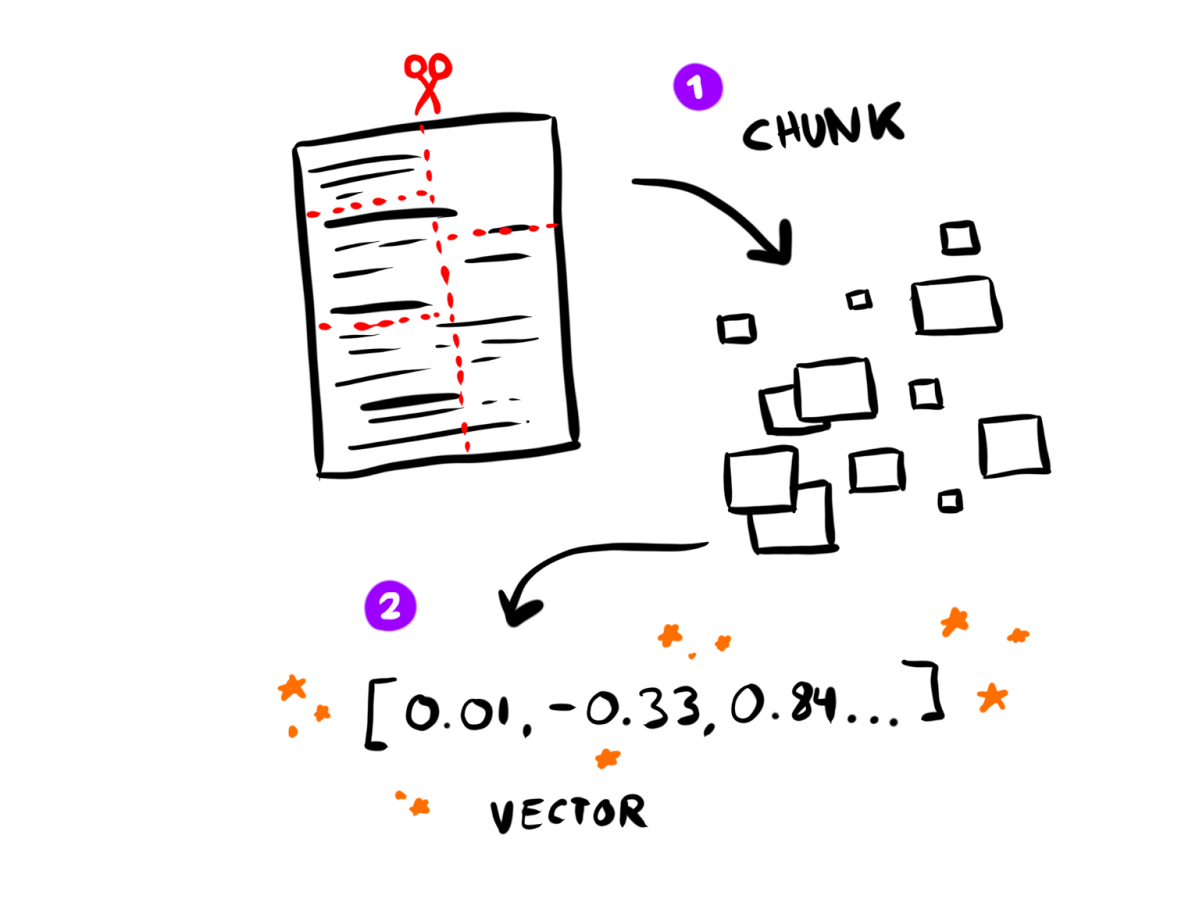
I like to think of vectors as a translation; this is your little chunk about feature configuration versioning written in the language of Math:
[
-0.006929283495992422,
-0.005336422007530928,
-4.547132266452536e-05,
-0.024047505110502243,
...
]See how they look like a list of coordinates? Visually, an embedding is like a ✨cluster of stars✨, and the index as the universe that contains them all.
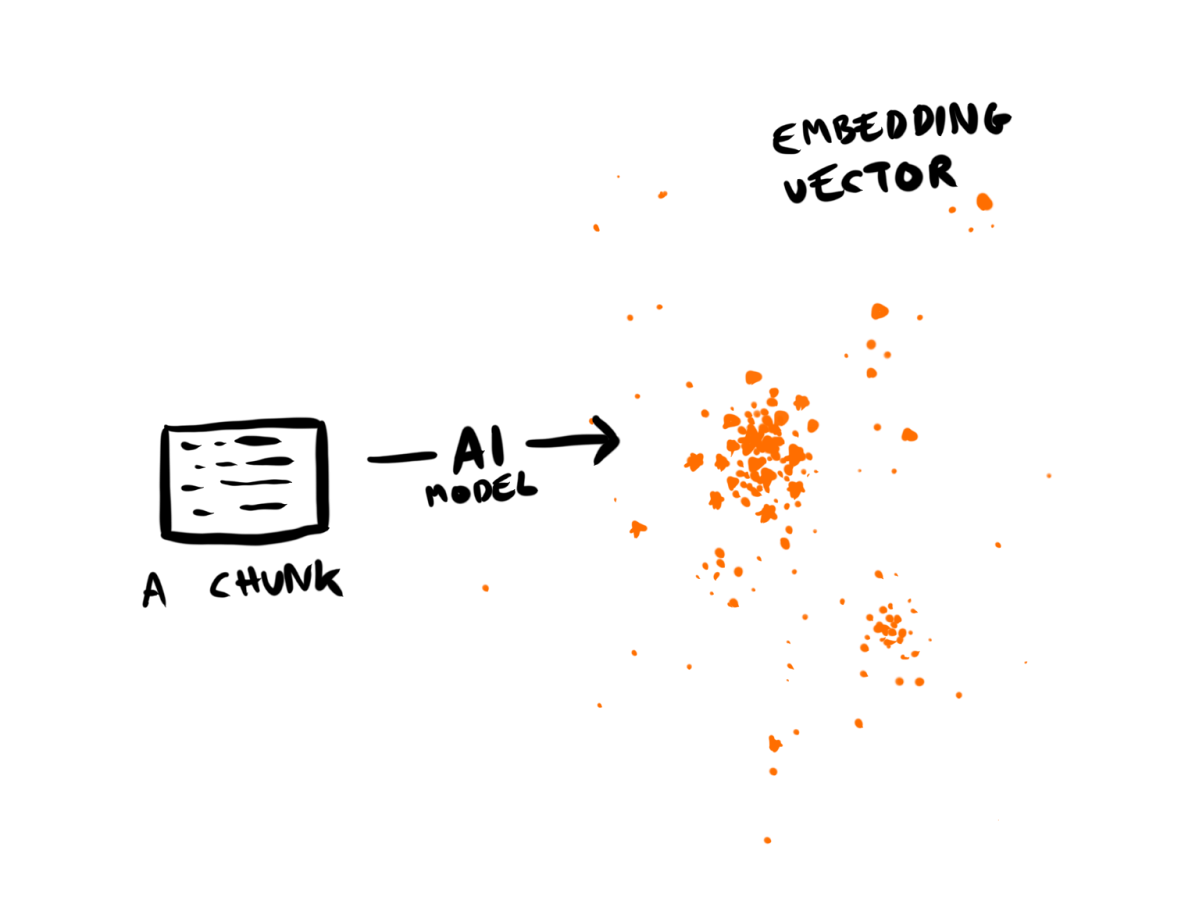
Each chunk and its associated embedding vector go into a search index, ready to be discovered. In this vast universe of content-as-math-as-stars, some star clusters overlap more than others (HINT: THIS IS FORESHADOWING!)
Magical math
What’s so cool about that? When Robotina executes a search, it uses that same embedding service to generate a vector of your question – a temporary cluster of stars. Then, rather than doing a plain text search, it looks for similar embeddings – clusters of stars that occupy the same space.

A piece of content about booking vacation overlaps a lot with phrases like ‘holiday’ or ‘time off’, or ‘PTO’ (Paid Time Off) – even if those words are not explicitly mentioned.
This is the cool part.
‘PTO’ does not exist in our wiki; it is an American word (initialism, technically). BUT, a search powered by embedding vectors will still return the “How to book vacation” page as the first hit when you search for “how to book PTO”. The language model knows that PTO, holiday, and vacation occupy the same linguistic space, and the embedding vectors reflect that. Stars literally align.
Math, man. I hated it when I was 12, but now it’s kind of cool.
Summarize!
Finally, Robotina (powered by a prompt that has gone through months and months of refinement) summarizes the search results that it receives and presents you with an answer. Effortless. 💅
Oh, but there’s more!
Embedding vectors are not infallible – they are cool, but in a huge index, there will be overlaps that make sense in Math but not in Human, particularly if the content is a bit ‘flabby’ (not tightly focused) or multiple domains use the same words. Nonsense happens.
The Docstack does things to ensure that Robotina receives relevant results from her brain. Here is a lil’ snapshot of techniques, all of which are still being refined.
Clarify, boost, filter, classify, domain-match, oh my
A question like “how do I configure feature X” is a little vague – are you a developer asking how to configure the backend of feature X, or a dashboard user, or something else?
- Compares the phrasing of your question to classify your intent – are you looking for documentation (“How does…”, “Explain how…”) or are you looking for methodology (“How do we…”, “What is our process for…”)?
- Compares your question to an embedding of domain terms to see if your question matches backend or LiveOps or narrative content – did you say ‘endpoint’? Request body? Probably a developer.
- Boosts, deboosts, and suppresses data sources and results with particular titles or paths based on the matching intent and domain.
As an additional safeguard, the Robotina system prompt is designed to ask for clarification and aggressively cite sources to reduce the risk of nonsense.
Glossaries and domain graphs
Unless you fine-tune it or train your own, a language model does not have access to the internal language of your company. Glossaries and domain graphs help Robotina understand that scheduled feature has a very specific meaning, and that waistcoat is synonymous with guitar pick (not really, but you know what I mean).
Doctective and discrepancies
On the content health side of things, Robotina’s sibling Doctective 🔍compares incoming content to existing content and uses AI to perform consistency checks. Have you already documented boop-boop-bleep? Do an embedding search! Does the incoming content contradict the existing content, or is there a ‘weird’ match? Compare the results! Refine your content!
Robotina, technical writing, and me
Although Robotina has grown into much more than a side-project and I currently write more prompts and code than docs, I still consider myself a technical writer. Documentation needs to exist before it can be leveraged by a robot, and someone needs to write it (or edit it, if it’s auto-generated by a code analysis pipeline – another promising Robotina sibling).
Ultimately, content structure and clarity determines the quality of your RAG pipeline output, and you can’t boost or filter your way out of bad writing.
Content is still king. Robotina and her gang are just tools to get the right content into the right hands at the right time with as little nonsense mixed in as possible.









